Having been to several physics conferences in the past, this time, I had the opportunity to go to a “tech” conference instead. For a week in May this year, I was in Barcelona, Spain, attending one of the largest open source software conferences in the world. Around 7,700 people from all over the world came together to share learnings, highlight innovation and discuss the future of “cloud native computing” at KubeCon + CloudNativeCon Europe 2019. “Kube” in the conference title refers to Kubernetes, an open-source platform that automates the deployment, scaling, and management of so-called software application containers. These containers can contain anything from a simple web server to a software framework that runs e.g. a machine learning training job. A big advantage is that containers isolate the software from the host system, making their execution not only safer, but also allowing for more uniform operation. All required software, libraries and configuration files are bundled in the container so that they can easily be copied and executed on other platforms. In addition, this enables full reproducibility as for instance desired by the data preservation efforts of the LHC experiments.
CMS has been using software containers since a while for grid jobs and the data set production system. For KubeCon Europe 2019, I had joined forces with a few colleagues from CERN (Ricardo Rocha, Thomas Hartland (both IT Department), Lukas Heinrich (EP Department)) to demonstrate that by orchestrating software containers and using the practically unlimited computing resources available in public clouds, a physics analysis, which usually takes hours to days, can be performed in minutes.
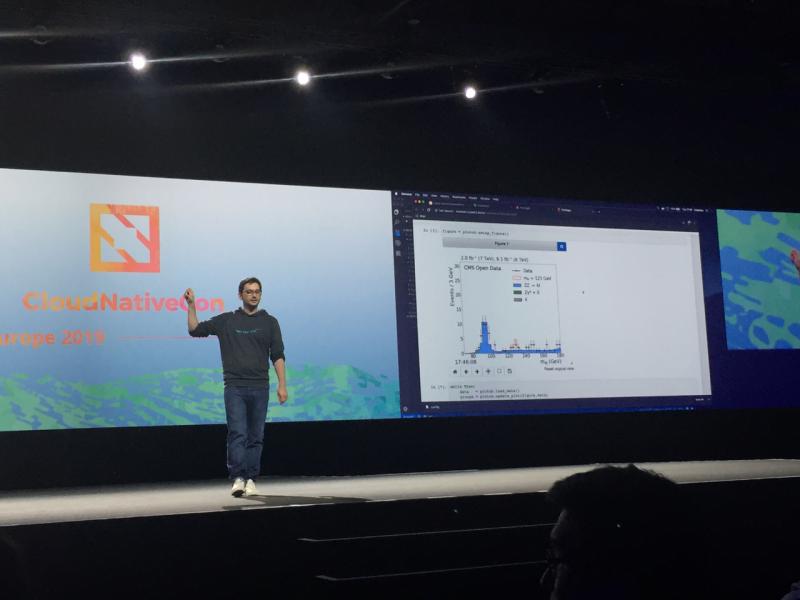
In order to be able to engage with the crowd at such a large conference, we had to come up with something special. Not everyone might be extremely interested in a high-energy physics analysis, but the Higgs boson has so far intrigued everyone. What better to do than show everyone the Higgs boson mass peak emerge from the data? Luckily, the CMS Open Data make this possible for anyone! So we were invited to give a keynote presentation, representing CERN in front of a huge crowd and we were very much relieved that the demonstration worked: the Higgs boson mass peak showed up within a few minutes after starting the jobs and the audience cheered! You can watch the video recording on YouTube. It was a great experience being part of such an endeavour. Also, everyone I talked to was excited to learn about CERN and the work we do here.

The technical background
The CMS Open Data team provides several examples of using the data, one of them being a simplified analysis of the Higgs boson decaying to four leptons via two Z bosons. The reconstruction of this final state is relatively easy—it’s just adding up the four-vectors of the four identified leptons to yield the Higgs boson mass. However, it also involves analysing the currently available 50% of the 2011 and 2012 data sets plus the corresponding simulation samples, amounting to about 70 Terabytes of data spread across 25,000 files. Thanks to a collaboration with Google through the CERN openlab , we were given credits so that we could scale to 25,000 CPU cores (cf. a few hundred batch jobs running in parallel on the CERN batch farm), allowing us to process one file per job in parallel.
However, while there are Linux software containers in which one can run the CMS software framework (CMSSW), the framework itself is usually mounted via the CernVM file system (CVMFS). To be able to use the public cloud, however, the full CMSSW release needs to be in the software container. Therefore, we built a new software container amounting to several Gigabytes in size that we could then schedule 25,000 times using Kubernetes within a few seconds.
The next challenge was to be able to process the data without bandwidth limitations. Streaming the data via the XRootD protocol works generally well, but for our purpose we needed to have the data as close to the CPUs as possible. Fortunately, the data are made available under the CC0 waiver, so we could copy them to the Google Cloud Storage where they will also be available in the future, and from there onto SSDs on the actual nodes for maximum throughput.
With this structure in place, we ended up with 25,000 ROOT files from which we had to make the plot of the reconstructed Higgs boson mass. Opening all these in one go gave us data corruption errors, so we had to find a solution to this problem. We eventually opted for streaming the filled histograms in a text-based (JSON) format into a in-memory database (Redis). From this database, we could then also read the entries using a python Jupyter notebook and update the plot every second.
One advantage of cloud computing is that you only pay for what you use: it turns out that with only around 1,000 CHF of cloud computing fees one can repeat our demonstration, i.e. process all relevant simulation and collision data sets from 2011 and 2012 in the cloud. This could for instance be used to write out the data into a smaller format that only contains the information required for further analysis. The big step forward here is that one does not need the grid or a batch farm such as the ones available only to high-energy physics experimentalists, but can orchestrate the CMSSW containers using Kubernetes on a public cloud service.
The views expressed in CMS blogs are personal views of the author and do not necessarily represent official views of the CMS collaboration.