The High-Luminosity LHC (HiLumi, or HL-LHC) is a scary prospect for those managing the data streams from the CMS experiment: moving to the projected higher luminosity era of the detector means a tenfold increase in data volume. That’s like going from travelling in a car to a plane. The difference is so huge! The goal for my team and I was to make sure we are well on our way to being able to handle this increase through the 2024 Data Challenge.
In preparation for HiLumi, the CMS detector is undergoing extensive reconstruction to capture more collision data than ever before. The higher the luminosity, the more data the LHC experiments can gather, so they need to be upgraded to fully harness this. The increase in data comes because of the increased number of ‘channels’ outputting data after the big detector upgrade, the larger number of particles in every snapshot we take due to increased luminosity, and the larger number of snapshots we decide to save.
Everything must be ready to go in 2030 - and that doesn’t leave much time to make sure that CMS is ready for the increase in data! CMS uses computing centres all around the world to store and process this data, taking advantage of sites and expertise in many countries.
In preparation for 2030, we set ourselves a challenge: gradually increase the amount and rate of data transferred between storage sites across the world. Eventually, we would be able to transfer the full amount of data needed safely! Here you can see the percentage of the total HL-LHC rate of data that we want to achieve in the time leading up to 2030.
| Year | % of HL-LHC |
|---|---|
| 2021 | 10 |
| 2024 | 25 |
| 2026 | 50 |
| 2028 | 100 |
The total amount of HL-LHC data is expected to be 350 Petabytes (or 350,000,000 Gigabytes!) per ‘Run’ period. A Run is typically 7 million seconds - an amount of time roughly equivalent to 81 days of continuous data taking! This is an incredible amount of data to be delivered over those 7 million seconds, meaning that the teams expect roughly 50 Gigabytes per second.
In addition to this, there is data from complex simulations that feed into the physics analysis, giving an estimated total rate of 250 GB/s!
Thankfully, the target for 2024 is only a quarter of the total rate, and so the base target is 62.5 GB/s. However, the data is not nicely and equally distributed across the Run’s time, and there may be some times when more data needs to be transferred than others. To account for this, the teams needed to double the rate and aim for 125 GB/s!
This is a big, ambitious rate, and much higher than our data transfer system normally works at, but everyone agreed we should push to achieve this target. For comparison, a high-quality video stream such as Netflix requires about 1MB/s for a good picture!
My team and I worked really hard to prepare in the 6 months before the Data Challenge 2024 (DC24). We tested using our software tools. Lisa helped me to decide how to split the rates between the 55 large and small CMS sites around the world. A lot of the data would come from CERN, since that is where the CMS detector is located. Several of the larger sites were tested in advance, to give the personnel there time to make improvements if necessary.
In the week before the challenge, there were some big worries…cables carrying data under the sea to the UK and the US from CERN snapped! Sometimes this happens, but this was very bad timing! Luckily, these were fixed in good time.
DC24 would last 12 days continuously, day and night. The plan was to spend the first week testing individual data flows, such as CERN to large sites, or large sites to small sites. In the second week, we would do all the transfers all at once, in order to really stress the system.
CMS was not the only experiment taking part in DC24: the other LHC experiments, ATLAS, LHCb and ALICE took part, with ATLAS setting themselves an even larger target than CMS! Other non-LHC experiments such as Belle-II and DUNE also joined in, as they use a lot of the same storage sites and network connections.
For CMS, week 1 went quite well. Panos, who’s working with me, operated the tool that created the data flows. We noticed a problem with ‘tokens’ which are a new way to ensure that only allowed entities can write or delete data in our storage systems. Testing the tokens was an extra dimension of the challenge. Overall, things went smoothly, but we knew that week 2 would be much more difficult.
We left the system running all over the weekend. I arrived at CERN to spend the week focussing on hitting the big target rate. As I studied it on Sunday night, I realised that we would need to make some significant changes to the File Transfer Service (FTS) in order to get close to the target. We needed to allow FTS to do more transfers simultaneously.
In the second week, Hasan, another member of the team, was operating the tool to create the data flows. We spent a lot of time in his office changing the parameters on FTS to allow more data to be transferred! Our colleague, Rahul kept a close eye on our data management system, Rucio. It was particularly important to check that data was being deleted as quickly as it was being transferred. We also saw other issues, such as problems at sites.
Every day we attended a meeting to report to the other experiments taking part, the FTS and Rucio teams, and the sites.
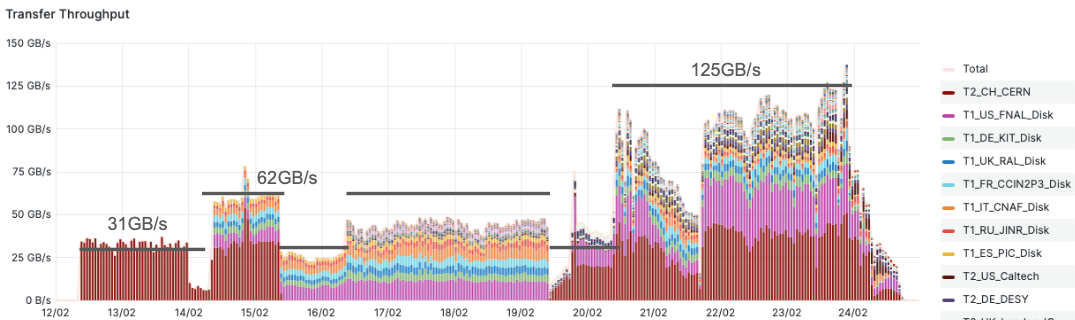
DC24 went very well for CMS, thanks to our detailed preparations and good collaboration with sites and software providers. We hit a lot of our targets but only just in some cases! We identified several ‘bottlenecks’ which reduce the rate of our transfers, and can be fixed before the next challenge, but showed that we have not ‘over-provisioned’ our system - i.e. we have not spent more money than needed. All in all, a great success.
Disclaimer: The views expressed in CMS blogs are personal views of the author and do not necessarily represent official views of the CMS collaboration.